Re: [firedrake] DMPlex in Firedrake: scaling of mesh distribution
On Fri, Mar 5, 2021 at 4:06 PM Alexei Colin <acolin@isi.edu> wrote:
To PETSc DMPlex users, Firedrake users, Dr. Knepley and Dr. Karpeev:
Is it expected for mesh distribution step to (A) take a share of 50-99% of total time-to-solution of an FEM problem, and
No
(B) take an amount of time that increases with the number of ranks, and
See below.
(C) take an amount of memory on rank 0 that does not decrease with the number of ranks
The problem here is that a serial mesh is being partitioned and sent to all processes. This is fundamentally non-scalable, but it is easy and works well for modest clusters < 100 nodes or so. Above this, it will take increasing amounts of time. There are a few techniques for mitigating this. a) For simple domains, you can distribute a coarse grid, then regularly refine that in parallel with DMRefine() or -dm_refine <k>. These steps can be repeated easily, and redistribution in parallel is fast, as shown for example in [1]. b) For complex meshes, you can read them in parallel, and then repeat a). This is done in [1]. It is a little more involved, but not much. c) You can do a multilevel partitioning, as they do in [2]. I cannot find the paper in which they describe this right now. It is feasible, but definitely the most expert approach. Does this make sense? Thanks, Matt [1] Fully Parallel Mesh I/O using PETSc DMPlex with an Application to Waveform Modeling, Hapla et.al. https://arxiv.org/abs/2004.08729 [2] On the robustness and performance of entropy stable discontinuous collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
On Sat, Mar 6, 2021 at 12:27 PM Matthew Knepley <knepley@buffalo.edu> wrote:
On Fri, Mar 5, 2021 at 4:06 PM Alexei Colin <acolin@isi.edu> wrote:
To PETSc DMPlex users, Firedrake users, Dr. Knepley and Dr. Karpeev:
Is it expected for mesh distribution step to (A) take a share of 50-99% of total time-to-solution of an FEM problem, and
No
(B) take an amount of time that increases with the number of ranks, and
See below.
(C) take an amount of memory on rank 0 that does not decrease with the number of ranks
The problem here is that a serial mesh is being partitioned and sent to all processes. This is fundamentally non-scalable, but it is easy and works well for modest clusters < 100 nodes or so. Above this, it will take increasing amounts of time. There are a few techniques for mitigating this.
Is this one-to-all communication only done once? If yes, one MPI_Scatterv() is enough and should not cost much. a) For simple domains, you can distribute a coarse grid, then regularly
refine that in parallel with DMRefine() or -dm_refine <k>. These steps can be repeated easily, and redistribution in parallel is fast, as shown for example in [1].
b) For complex meshes, you can read them in parallel, and then repeat a). This is done in [1]. It is a little more involved, but not much.
c) You can do a multilevel partitioning, as they do in [2]. I cannot find the paper in which they describe this right now. It is feasible, but definitely the most expert approach.
Does this make sense?
Thanks,
Matt
[1] Fully Parallel Mesh I/O using PETSc DMPlex with an Application to Waveform Modeling, Hapla et.al. https://arxiv.org/abs/2004.08729 [2] On the robustness and performance of entropy stable discontinuous collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
I observed poor scaling with mat/tests/ex13 on Fugaku recently. I was running this test as is (eg, no threads and 4 MPI processes per node/chip, which seems recomended). I did not dig into this. A test with about 10% of the machine took about 45 minutes to run. Mark On Sat, Mar 6, 2021 at 9:49 PM Junchao Zhang <junchao.zhang@gmail.com> wrote:
On Sat, Mar 6, 2021 at 12:27 PM Matthew Knepley <knepley@buffalo.edu> wrote:
On Fri, Mar 5, 2021 at 4:06 PM Alexei Colin <acolin@isi.edu> wrote:
To PETSc DMPlex users, Firedrake users, Dr. Knepley and Dr. Karpeev:
Is it expected for mesh distribution step to (A) take a share of 50-99% of total time-to-solution of an FEM problem, and
No
(B) take an amount of time that increases with the number of ranks, and
See below.
(C) take an amount of memory on rank 0 that does not decrease with the number of ranks
The problem here is that a serial mesh is being partitioned and sent to all processes. This is fundamentally non-scalable, but it is easy and works well for modest clusters < 100 nodes or so. Above this, it will take increasing amounts of time. There are a few techniques for mitigating this.
Is this one-to-all communication only done once? If yes, one MPI_Scatterv() is enough and should not cost much.
a) For simple domains, you can distribute a coarse grid, then regularly
refine that in parallel with DMRefine() or -dm_refine <k>. These steps can be repeated easily, and redistribution in parallel is fast, as shown for example in [1].
b) For complex meshes, you can read them in parallel, and then repeat a). This is done in [1]. It is a little more involved, but not much.
c) You can do a multilevel partitioning, as they do in [2]. I cannot find the paper in which they describe this right now. It is feasible, but definitely the most expert approach.
Does this make sense?
Thanks,
Matt
[1] Fully Parallel Mesh I/O using PETSc DMPlex with an Application to Waveform Modeling, Hapla et.al. https://arxiv.org/abs/2004.08729 [2] On the robustness and performance of entropy stable discontinuous collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
mat/tests/ex13.c creates a sequential AIJ matrix, converts it to the same format, reorders it and then prints it and the reordering in ASCII. Each of these steps is sequential and takes place on each rank. The prints are ASCII stdout on the ranks. ierr = MatCreateSeqAIJ(PETSC_COMM_SELF,m*n,m*n,5,NULL,&C);CHKERRQ(ierr); /* create the matrix for the five point stencil, YET AGAIN*/ for (i=0; i<m; i++) { for (j=0; j<n; j++) { v = -1.0; Ii = j + n*i; if (i>0) {J = Ii - n; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (i<m-1) {J = Ii + n; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (j>0) {J = Ii - 1; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (j<n-1) {J = Ii + 1; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} v = 4.0; ierr = MatSetValues(C,1,&Ii,1,&Ii,&v,INSERT_VALUES);CHKERRQ(ierr); } } ierr = MatAssemblyBegin(C,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr); ierr = MatAssemblyEnd(C,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr); ierr = MatConvert(C,MATSAME,MAT_INITIAL_MATRIX,&A);CHKERRQ(ierr); ierr = MatGetOrdering(A,MATORDERINGND,&perm,&iperm);CHKERRQ(ierr); ierr = ISView(perm,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr); ierr = ISView(iperm,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr); ierr = MatView(A,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr); I think each rank would simply be running the same code and dumping everything to its own stdout. At some point within the system/MPI executor there is code that merges and print outs the stdout of each rank. If the test does truly take 45 minutes than Fugaku has a classic bug of not being able to efficiently merge stdout from each of the ranks. Nothing really to do with PETSc, just neglect of Fugaku developers to respect all aspects of developing a HPC system. Heck, they only had a billion dollars, can't expect them to do what other scalable systems do :-). One should be able to reproduce this with a simple MPI program that prints a moderate amount of data to stdout on each rank. Barry
On Mar 6, 2021, at 9:46 PM, Mark Adams <mfadams@lbl.gov> wrote:
I observed poor scaling with mat/tests/ex13 on Fugaku recently. I was running this test as is (eg, no threads and 4 MPI processes per node/chip, which seems recomended). I did not dig into this. A test with about 10% of the machine took about 45 minutes to run. Mark
On Sat, Mar 6, 2021 at 9:49 PM Junchao Zhang <junchao.zhang@gmail.com <mailto:junchao.zhang@gmail.com>> wrote:
On Sat, Mar 6, 2021 at 12:27 PM Matthew Knepley <knepley@buffalo.edu <mailto:knepley@buffalo.edu>> wrote: On Fri, Mar 5, 2021 at 4:06 PM Alexei Colin <acolin@isi.edu <mailto:acolin@isi.edu>> wrote: To PETSc DMPlex users, Firedrake users, Dr. Knepley and Dr. Karpeev:
Is it expected for mesh distribution step to (A) take a share of 50-99% of total time-to-solution of an FEM problem, and
No
(B) take an amount of time that increases with the number of ranks, and
See below.
(C) take an amount of memory on rank 0 that does not decrease with the number of ranks
The problem here is that a serial mesh is being partitioned and sent to all processes. This is fundamentally non-scalable, but it is easy and works well for modest clusters < 100 nodes or so. Above this, it will take increasing amounts of time. There are a few techniques for mitigating this. Is this one-to-all communication only done once? If yes, one MPI_Scatterv() is enough and should not cost much.
a) For simple domains, you can distribute a coarse grid, then regularly refine that in parallel with DMRefine() or -dm_refine <k>. These steps can be repeated easily, and redistribution in parallel is fast, as shown for example in [1].
b) For complex meshes, you can read them in parallel, and then repeat a). This is done in [1]. It is a little more involved, but not much.
c) You can do a multilevel partitioning, as they do in [2]. I cannot find the paper in which they describe this right now. It is feasible, but definitely the most expert approach.
Does this make sense?
Thanks,
Matt
[1] Fully Parallel Mesh I/O using PETSc DMPlex with an Application to Waveform Modeling, Hapla et.al <http://et.al/>. https://arxiv.org/abs/2004.08729 <https://arxiv.org/abs/2004.08729> [2] On the robustness and performance of entropy stable discontinuous collocation methods for the compressible Navier-Stokes equations, ROjas .et.al <http://et.al/>. https://arxiv.org/abs/1911.10966 <https://arxiv.org/abs/1911.10966>
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr... <https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedrake_cahn_hilliard_problem.py>
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf <https://arxiv.org/pdf/1506.06194.pdf>
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749 <http://arxiv.org/abs/1506.07749>
Whoop, snes/tests/ex13.c. This is what I used for the Summit runs that I presented a while ago. On Sun, Mar 7, 2021 at 6:12 AM Barry Smith <bsmith@petsc.dev> wrote:
mat/tests/ex13.c creates a sequential AIJ matrix, converts it to the same format, reorders it and then prints it and the reordering in ASCII. Each of these steps is sequential and takes place on each rank. The prints are ASCII stdout on the ranks.
ierr = MatCreateSeqAIJ(PETSC_COMM_SELF,m*n,m*n,5,NULL,&C);CHKERRQ(ierr); /* create the matrix for the five point stencil, YET AGAIN*/ for (i=0; i<m; i++) { for (j=0; j<n; j++) { v = -1.0; Ii = j + n*i; if (i>0) {J = Ii - n; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (i<m-1) {J = Ii + n; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (j>0) {J = Ii - 1; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} if (j<n-1) {J = Ii + 1; ierr = MatSetValues(C,1,&Ii,1,&J,&v,INSERT_VALUES);CHKERRQ(ierr);} v = 4.0; ierr = MatSetValues(C,1,&Ii,1,&Ii,&v,INSERT_VALUES);CHKERRQ(ierr); } } ierr = MatAssemblyBegin(C,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr); ierr = MatAssemblyEnd(C,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
ierr = MatConvert(C,MATSAME,MAT_INITIAL_MATRIX,&A);CHKERRQ(ierr);
ierr = MatGetOrdering(A,MATORDERINGND,&perm,&iperm);CHKERRQ(ierr); ierr = ISView(perm,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr); ierr = ISView(iperm,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr); ierr = MatView(A,PETSC_VIEWER_STDOUT_SELF);CHKERRQ(ierr);
I think each rank would simply be running the same code and dumping everything to its own stdout.
At some point within the system/MPI executor there is code that merges and print outs the stdout of each rank. If the test does truly take 45 minutes than Fugaku has a classic bug of not being able to efficiently merge stdout from each of the ranks. Nothing really to do with PETSc, just neglect of Fugaku developers to respect all aspects of developing a HPC system. Heck, they only had a billion dollars, can't expect them to do what other scalable systems do :-).
One should be able to reproduce this with a simple MPI program that prints a moderate amount of data to stdout on each rank.
Barry
On Mar 6, 2021, at 9:46 PM, Mark Adams <mfadams@lbl.gov> wrote:
I observed poor scaling with mat/tests/ex13 on Fugaku recently. I was running this test as is (eg, no threads and 4 MPI processes per node/chip, which seems recomended). I did not dig into this. A test with about 10% of the machine took about 45 minutes to run. Mark
On Sat, Mar 6, 2021 at 9:49 PM Junchao Zhang <junchao.zhang@gmail.com> wrote:
On Sat, Mar 6, 2021 at 12:27 PM Matthew Knepley <knepley@buffalo.edu> wrote:
On Fri, Mar 5, 2021 at 4:06 PM Alexei Colin <acolin@isi.edu> wrote:
To PETSc DMPlex users, Firedrake users, Dr. Knepley and Dr. Karpeev:
Is it expected for mesh distribution step to (A) take a share of 50-99% of total time-to-solution of an FEM problem, and
No
(B) take an amount of time that increases with the number of ranks, and
See below.
(C) take an amount of memory on rank 0 that does not decrease with the number of ranks
The problem here is that a serial mesh is being partitioned and sent to all processes. This is fundamentally non-scalable, but it is easy and works well for modest clusters < 100 nodes or so. Above this, it will take increasing amounts of time. There are a few techniques for mitigating this.
Is this one-to-all communication only done once? If yes, one MPI_Scatterv() is enough and should not cost much.
a) For simple domains, you can distribute a coarse grid, then regularly
refine that in parallel with DMRefine() or -dm_refine <k>. These steps can be repeated easily, and redistribution in parallel is fast, as shown for example in [1].
b) For complex meshes, you can read them in parallel, and then repeat a). This is done in [1]. It is a little more involved, but not much.
c) You can do a multilevel partitioning, as they do in [2]. I cannot find the paper in which they describe this right now. It is feasible, but definitely the most expert approach.
Does this make sense?
Thanks,
Matt
[1] Fully Parallel Mesh I/O using PETSc DMPlex with an Application to Waveform Modeling, Hapla et.al. https://arxiv.org/abs/2004.08729 [2] On the robustness and performance of entropy stable discontinuous collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
[2] On the robustness and performance of entropy stable discontinuous
collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
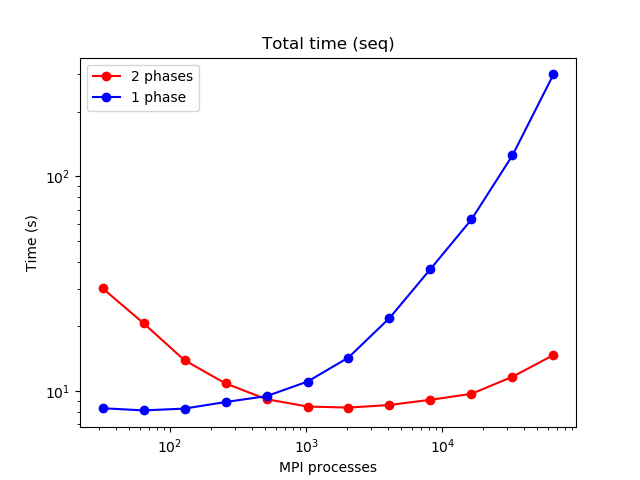
This is not the proper reference, here is the correct one https://www.sciencedirect.com/science/article/pii/S0021999120306185?dgcid=rs... However, there the algorithm is only outlined, and performances related to the mesh distribution are not really reported. We observed a large gain for large core counts and one to all distributions (from minutes to seconds) by splitting the several communication rounds needed by DMPlex into stages: from rank 0 to 1 rank per node, and then decomposing independently within the node. Attached the total time for one-to-all DMPlexDistrbute for a 128^3 mesh
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
-- Stefano
{kind=link}
Is phase 1 the old method and 2 the new? Is this 128^3 mesh per process? On Sun, Mar 7, 2021 at 7:27 AM Stefano Zampini <stefano.zampini@gmail.com> wrote:
[2] On the robustness and performance of entropy stable discontinuous
collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
This is not the proper reference, here is the correct one https://www.sciencedirect.com/science/article/pii/S0021999120306185?dgcid=rs... However, there the algorithm is only outlined, and performances related to the mesh distribution are not really reported. We observed a large gain for large core counts and one to all distributions (from minutes to seconds) by splitting the several communication rounds needed by DMPlex into stages: from rank 0 to 1 rank per node, and then decomposing independently within the node. Attached the total time for one-to-all DMPlexDistrbute for a 128^3 mesh
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
-- Stefano
128^3 is the entire mesh. The blue line (1 phase) is with dmplexdistribute, the red line, with a two-stage approach. Il Dom 7 Mar 2021, 16:20 Mark Adams <mfadams@lbl.gov> ha scritto:
Is phase 1 the old method and 2 the new? Is this 128^3 mesh per process?
On Sun, Mar 7, 2021 at 7:27 AM Stefano Zampini <stefano.zampini@gmail.com> wrote:
[2] On the robustness and performance of entropy stable discontinuous
collocation methods for the compressible Navier-Stokes equations, ROjas . et.al. https://arxiv.org/abs/1911.10966
This is not the proper reference, here is the correct one https://www.sciencedirect.com/science/article/pii/S0021999120306185?dgcid=rs... However, there the algorithm is only outlined, and performances related to the mesh distribution are not really reported. We observed a large gain for large core counts and one to all distributions (from minutes to seconds) by splitting the several communication rounds needed by DMPlex into stages: from rank 0 to 1 rank per node, and then decomposing independently within the node. Attached the total time for one-to-all DMPlexDistrbute for a 128^3 mesh
?
The attached plots suggest (A), (B), and (C) is happening for Cahn-Hilliard problem (from firedrake-bench repo) on a 2D 8Kx8K unit-square mesh. The implementation is here [1]. Versions are Firedrake, PyOp2: 20200204.0; PETSc 3.13.1; ParMETIS 4.0.3.
Two questions, one on (A) and the other on (B)+(C):
1. Is (A) result expected? Given (A), any effort to improve the quality of the compiled assembly kernels (or anything else other than mesh distribution) appears futile since it takes 1% of end-to-end execution time, or am I missing something?
1a. Is mesh distribution fundamentally necessary for any FEM framework, or is it only needed by Firedrake? If latter, then how do other frameworks partition the mesh and execute in parallel with MPI but avoid the non-scalable mesh destribution step?
2. Results (B) and (C) suggest that the mesh distribution step does not scale. Is it a fundamental property of the mesh distribution problem that it has a central bottleneck in the master process, or is it a limitation of the current implementation in PETSc-DMPlex?
2a. Our (B) result seems to agree with Figure 4(left) of [2]. Fig 6 of [2] suggests a way to reduce the time spent on sequential bottleneck by "parallel mesh refinment" that creates high-resolution meshes from an initial coarse mesh. Is this approach implemented in DMPLex? If so, any pointers on how to try it out with Firedrake? If not, any other directions for reducing this bottleneck?
2b. Fig 6 in [3] shows plots for Assembly and Solve steps that scale well up to 96 cores -- is mesh distribution included in those times? Is anyone reading this aware of any other publications with evaluations of Firedrake that measure mesh distribution (or explain how to avoid or exclude it)?
Thank you for your time and any info or tips.
[1] https://github.com/ISI-apex/firedrake-bench/blob/master/cahn_hilliard/firedr...
[2] Unstructured Overlapping Mesh Distribution in Parallel, Matthew G. Knepley, Michael Lange, Gerard J. Gorman, 2015. https://arxiv.org/pdf/1506.06194.pdf
[3] Efficient mesh management in Firedrake using PETSc-DMPlex, Michael Lange, Lawrence Mitchell, Matthew G. Knepley and Gerard J. Gorman, SISC, 38(5), S143-S155, 2016. http://arxiv.org/abs/1506.07749
-- Stefano
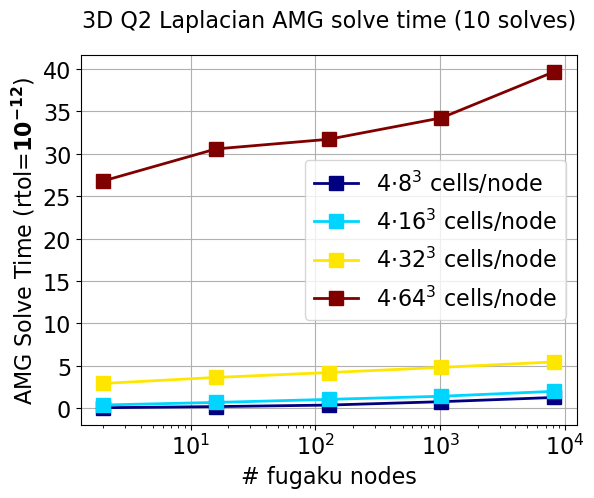
FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling. 0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 ************************************************************************************************************************ *** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document *** ************************************************************************************************************************ ---------------------------------------------- PETSc Performance Summary: ---------------------------------------------- ../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb 12 23:27:13 2021 Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000 Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000 Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7% ------------------------------------------------------------------------------------------------------------------------ See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors) ------------------------------------------------------------------------------------------------------------------------ Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s ------------------------------------------------------------------------------------------------------------------------ --- Event Stage 0: Main Stage PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06 7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0 BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967 --- Event Stage 1: PCSetUp BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463 --- Event Stage 2: KSP Solve only SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360 ------------------------------------------------------------------------------------------------------------------------ Memory usage is given in bytes: Object Type Creations Destructions Memory Descendants' Mem. Reports information only for process 0. --- Event Stage 0: Main Stage Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0. --- Event Stage 1: PCSetUp Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0. --- Event Stage 2: KSP Solve only Index Set 5 5 8296 0. Matrix 1 1 273856 0. ======================================================================================================================== Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: ----------------------------------------- Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast ----------------------------------------- Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include ----------------------------------------- Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
{kind=link}
And this data puts one cell per process, distributes, and then refines 5 (or 2,3,4 in plot) times. On Sun, Mar 7, 2021 at 8:27 AM Mark Adams <mfadams@lbl.gov> wrote:
FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling.
0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22
************************************************************************************************************************ *** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document ***
************************************************************************************************************************
---------------------------------------------- PETSc Performance Summary: ----------------------------------------------
../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb 12 23:27:13 2021 Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000
Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000
Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop
Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7%
------------------------------------------------------------------------------------------------------------------------ See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors)
------------------------------------------------------------------------------------------------------------------------ Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s
------------------------------------------------------------------------------------------------------------------------
--- Event Stage 0: Main Stage
PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06 7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0 BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967
--- Event Stage 1: PCSetUp
BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463
--- Event Stage 2: KSP Solve only
SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360
------------------------------------------------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem. Reports information only for process 0.
--- Event Stage 0: Main Stage
Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0.
--- Event Stage 1: PCSetUp
Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0.
--- Event Stage 2: KSP Solve only
Index Set 5 5 8296 0. Matrix 1 1 273856 0.
======================================================================================================================== Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: -----------------------------------------
Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast -----------------------------------------
Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include -----------------------------------------
Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
Mark, Thanks for the numbers. Extremely problematic. DMPlexDistribute takes 88 percent of the total run time, SFBcastOpEnd takes 80 percent. Probably Matt is right, PetscSF is flooding the network which it cannot handle. IMHO fixing PetscSF would be a far better route than writing all kinds of fancy DMPLEX hierarchical distributors. PetscSF needs to detect that it is sending too many messages together and do the messaging in appropriate waves; at the moment PetscSF is as dumb as stone it just shoves everything out as fast as it can. Junchao needs access to this machine. If everything in PETSc will depend on PetscSF then it simply has to scale on systems where you cannot just flood the network with MPI. Barry Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+00.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+00.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0
On Mar 7, 2021, at 7:35 AM, Mark Adams <mfadams@lbl.gov> wrote:
And this data puts one cell per process, distributes, and then refines 5 (or 2,3,4 in plot) times.
On Sun, Mar 7, 2021 at 8:27 AM Mark Adams <mfadams@lbl.gov <mailto:mfadams@lbl.gov>> wrote: FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling.
0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 ************************************************************************************************************************ *** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document *** ************************************************************************************************************************
---------------------------------------------- PETSc Performance Summary: ----------------------------------------------
../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb 12 23:27:13 2021 Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000
Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000
Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop
Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7%
------------------------------------------------------------------------------------------------------------------------ See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors) ------------------------------------------------------------------------------------------------------------------------ Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s ------------------------------------------------------------------------------------------------------------------------
--- Event Stage 0: Main Stage
PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06 7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0 BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967
--- Event Stage 1: PCSetUp
BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463
--- Event Stage 2: KSP Solve only
SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360 ------------------------------------------------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem. Reports information only for process 0.
--- Event Stage 0: Main Stage
Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0.
--- Event Stage 1: PCSetUp
Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0.
--- Event Stage 2: KSP Solve only
Index Set 5 5 8296 0. Matrix 1 1 273856 0. ======================================================================================================================== Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: -----------------------------------------
Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast -----------------------------------------
Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include -----------------------------------------
Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
Mark Being an MPI issue, you should run with -log_sync From your log the problem seems with SFSetup that is called many times (62), with timings associated mostly to the SF revealing ranks phase. DMPlex abuses of the embedded SF, that can be optimized further I presume. It should run (someone has to write the code) a cheaper operation, since the communication graph of the embedded SF is a subgraph of the original .
On Mar 7, 2021, at 10:01 PM, Barry Smith <bsmith@petsc.dev> wrote:
Mark,
Thanks for the numbers.
Extremely problematic. DMPlexDistribute takes 88 percent of the total run time, SFBcastOpEnd takes 80 percent.
Probably Matt is right, PetscSF is flooding the network which it cannot handle. IMHO fixing PetscSF would be a far better route than writing all kinds of fancy DMPLEX hierarchical distributors. PetscSF needs to detect that it is sending too many messages together and do the messaging in appropriate waves; at the moment PetscSF is as dumb as stone it just shoves everything out as fast as it can. Junchao needs access to this machine. If everything in PETSc will depend on PetscSF then it simply has to scale on systems where you cannot just flood the network with MPI.
Barry
Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+00.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+00.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0
On Mar 7, 2021, at 7:35 AM, Mark Adams <mfadams@lbl.gov <mailto:mfadams@lbl.gov>> wrote:
And this data puts one cell per process, distributes, and then refines 5 (or 2,3,4 in plot) times.
On Sun, Mar 7, 2021 at 8:27 AM Mark Adams <mfadams@lbl.gov <mailto:mfadams@lbl.gov>> wrote: FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling.
0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 ************************************************************************************************************************ *** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document *** ************************************************************************************************************************
---------------------------------------------- PETSc Performance Summary: ----------------------------------------------
../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb 12 23:27:13 2021 Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000
Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000
Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop
Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7%
------------------------------------------------------------------------------------------------------------------------ See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors) ------------------------------------------------------------------------------------------------------------------------ Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s ------------------------------------------------------------------------------------------------------------------------
--- Event Stage 0: Main Stage
PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06 7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0 BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967
--- Event Stage 1: PCSetUp
BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463
--- Event Stage 2: KSP Solve only
SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360 ------------------------------------------------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem. Reports information only for process 0.
--- Event Stage 0: Main Stage
Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0.
--- Event Stage 1: PCSetUp
Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0.
--- Event Stage 2: KSP Solve only
Index Set 5 5 8296 0. Matrix 1 1 273856 0. ======================================================================================================================== Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: -----------------------------------------
Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast -----------------------------------------
Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include -----------------------------------------
Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
There is some use of Iscatterv in SF implementations (though it looks like perhaps not PetscSFBcast where the root nodes are consolidated on a root rank). We should perhaps have a function that analyzes the graph to set the type rather than requiring the caller to PetscSFSetType. Barry Smith <bsmith@petsc.dev> writes:
Mark,
Thanks for the numbers.
Extremely problematic. DMPlexDistribute takes 88 percent of the total run time, SFBcastOpEnd takes 80 percent.
Probably Matt is right, PetscSF is flooding the network which it cannot handle. IMHO fixing PetscSF would be a far better route than writing all kinds of fancy DMPLEX hierarchical distributors. PetscSF needs to detect that it is sending too many messages together and do the messaging in appropriate waves; at the moment PetscSF is as dumb as stone it just shoves everything out as fast as it can. Junchao needs access to this machine. If everything in PETSc will depend on PetscSF then it simply has to scale on systems where you cannot just flood the network with MPI.
Barry
Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+00.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+00.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0
On Mar 7, 2021, at 7:35 AM, Mark Adams <mfadams@lbl.gov> wrote:
And this data puts one cell per process, distributes, and then refines 5 (or 2,3,4 in plot) times.
On Sun, Mar 7, 2021 at 8:27 AM Mark Adams <mfadams@lbl.gov <mailto:mfadams@lbl.gov>> wrote: FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling.
0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 ************************************************************************************************************************ *** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document *** ************************************************************************************************************************
---------------------------------------------- PETSc Performance Summary: ----------------------------------------------
../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb 12 23:27:13 2021 Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000
Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000
Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop
Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7%
------------------------------------------------------------------------------------------------------------------------ See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors) ------------------------------------------------------------------------------------------------------------------------ Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s ------------------------------------------------------------------------------------------------------------------------
--- Event Stage 0: Main Stage
PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06 7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0 BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967
--- Event Stage 1: PCSetUp
BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463
--- Event Stage 2: KSP Solve only
SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360 ------------------------------------------------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem. Reports information only for process 0.
--- Event Stage 0: Main Stage
Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0.
--- Event Stage 1: PCSetUp
Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0.
--- Event Stage 2: KSP Solve only
Index Set 5 5 8296 0. Matrix 1 1 273856 0. ======================================================================================================================== Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: -----------------------------------------
Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast -----------------------------------------
Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include -----------------------------------------
Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
Yes, we should investigate whether DMPlex used PetscSF in a wrong way or PetscSF needs to detect this pattern. I need to learn more about DMPlex. --Junchao Zhang On Sun, Mar 7, 2021 at 6:40 PM Jed Brown <jed@jedbrown.org> wrote:
There is some use of Iscatterv in SF implementations (though it looks like perhaps not PetscSFBcast where the root nodes are consolidated on a root rank).
We should perhaps have a function that analyzes the graph to set the type rather than requiring the caller to PetscSFSetType.
Barry Smith <bsmith@petsc.dev> writes:
Mark,
Thanks for the numbers.
Extremely problematic. DMPlexDistribute takes 88 percent of the total run time, SFBcastOpEnd takes 80 percent.
Probably Matt is right, PetscSF is flooding the network which it cannot handle. IMHO fixing PetscSF would be a far better route than writing all kinds of fancy DMPLEX hierarchical distributors. PetscSF needs to detect that it is sending too many messages together and do the messaging in appropriate waves; at the moment PetscSF is as dumb as stone it just shoves everything out as fast as it can. Junchao needs access to this machine. If everything in PETSc will depend on PetscSF then it simply has to scale on systems where you cannot just flood the network with MPI.
Barry
Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+00.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+00.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0
On Mar 7, 2021, at 7:35 AM, Mark Adams <mfadams@lbl.gov> wrote:
And this data puts one cell per process, distributes, and then refines 5 (or 2,3,4 in plot) times.
On Sun, Mar 7, 2021 at 8:27 AM Mark Adams <mfadams@lbl.gov <mailto: mfadams@lbl.gov>> wrote: FWIW, Here is the output from ex13 on 32K processes (8K Fugaku nodes/sockets, 4 MPI/node, which seems recommended) with 128^3 vertex mesh (64^3 Q2 3D Laplacian). Almost an hour. Attached is solver scaling.
0 SNES Function norm 3.658334849208e+00 Linear solve converged due to CONVERGED_RTOL iterations 22 1 SNES Function norm 1.609000373074e-12 Nonlinear solve converged due to CONVERGED_ITS iterations 1 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22 Linear solve converged due to CONVERGED_RTOL iterations 22
*** WIDEN YOUR WINDOW TO 120 CHARACTERS. Use 'enscript -r -fCourier9' to print this document ***
---------------------------------------------- PETSc Performance
Summary: ----------------------------------------------
../ex13 on a named i07-4008c with 32768 processors, by a04199 Fri Feb
12 23:27:13 2021
Using Petsc Development GIT revision: v3.14.4-579-g4cb72fa GIT Date: 2021-02-05 15:19:40 +0000
Max Max/Min Avg Total Time (sec): 3.373e+03 1.000 3.373e+03 Objects: 1.055e+05 14.797 7.144e+03 Flop: 5.376e+10 1.176 4.885e+10 1.601e+15 Flop/sec: 1.594e+07 1.176 1.448e+07 4.745e+11 MPI Messages: 6.048e+05 30.010 8.833e+04 2.894e+09 MPI Message Lengths: 1.127e+09 4.132 6.660e+03 1.928e+13 MPI Reductions: 1.824e+03 1.000
Flop counting convention: 1 flop = 1 real number operation of type (multiply/divide/add/subtract) e.g., VecAXPY() for real vectors of length N --> 2N flop and VecAXPY() for complex vectors of length N --> 8N flop
Summary of Stages: ----- Time ------ ----- Flop ------ --- Messages --- -- Message Lengths -- -- Reductions -- Avg %Total Avg %Total Count %Total Avg %Total Count %Total 0: Main Stage: 3.2903e+03 97.5% 2.4753e+14 15.5% 3.538e+08 12.2% 1.779e+04 32.7% 9.870e+02 54.1% 1: PCSetUp: 4.3062e+01 1.3% 1.8160e+13 1.1% 1.902e+07 0.7% 3.714e+04 3.7% 1.590e+02 8.7% 2: KSP Solve only: 3.9685e+01 1.2% 1.3349e+15 83.4% 2.522e+09 87.1% 4.868e+03 63.7% 6.700e+02 36.7%
See the 'Profiling' chapter of the users' manual for details on interpreting output. Phase summary info: Count: number of times phase was executed Time and Flop: Max - maximum over all processors Ratio - ratio of maximum to minimum over all processors Mess: number of messages sent AvgLen: average message length (bytes) Reduct: number of global reductions Global: entire computation Stage: stages of a computation. Set stages with PetscLogStagePush() and PetscLogStagePop(). %T - percent time in this phase %F - percent flop in this phase %M - percent messages in this phase %L - percent message lengths in this phase %R - percent reductions in this phase Total Mflop/s: 10e-6 * (sum of flop over all processors)/(max time over all processors)
Event Count Time (sec) Flop --- Global --- --- Stage ---- Total Max Ratio Max Ratio Max Ratio Mess AvgLen Reduct %T %F %M %L %R %T %F %M %L %R Mflop/s
--- Event Stage 0: Main Stage
PetscBarrier 5 1.0 1.9907e+00 2.2 0.00e+00 0.0 3.8e+06
7.7e+01 2.0e+01 0 0 0 0 1 0 0 1 0 2 0
BuildTwoSided 62 1.0 7.3272e+0214.1 0.00e+00 0.0 6.7e+06 8.0e+00 0.0e+00 5 0 0 0 0 5 0 2 0 0 0 BuildTwoSidedF 59 1.0 3.1132e+01 7.4 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 SNESSolve 1 1.0 1.7468e+02 1.0 7.83e+09 1.3 3.4e+08 1.3e+04 8.8e+02 5 13 12 23 48 5 85 96 70 89 1205779 SNESSetUp 1 1.0 2.4195e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 SNESFunctionEval 3 1.0 1.1359e+01 1.2 1.17e+09 1.0 1.6e+06 1.4e+04 2.0e+00 0 2 0 0 0 0 15 0 0 0 3344744 SNESJacobianEval 2 1.0 1.6829e+02 1.0 1.52e+09 1.0 1.1e+06 8.3e+05 0.0e+00 5 3 0 5 0 5 20 0 14 0 293588 DMCreateMat 1 1.0 2.4107e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.3e+01 1 0 0 7 1 1 0 1 22 1 0 Mesh Partition 1 1.0 5.0133e+02 1.0 0.00e+00 0.0 1.3e+05 2.7e+02 6.0e+00 15 0 0 0 0 15 0 0 0 1 0 Mesh Migration 1 1.0 1.5494e+03 1.0 0.00e+00 0.0 7.3e+05 1.9e+02 2.4e+01 45 0 0 0 1 46 0 0 0 2 0 DMPlexPartSelf 1 1.0 1.1498e+002367.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblInv 1 1.0 3.6698e+00 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartLblSF 1 1.0 2.8522e-01 1.7 0.00e+00 0.0 4.9e+04 1.5e+02 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPartStrtSF 1 1.0 4.9474e+023520.8 0.00e+00 0.0 3.3e+04 4.3e+02 0.0e+00 14 0 0 0 0 15 0 0 0 0 0 DMPlexPointSF 1 1.0 9.8750e+021264.8 0.00e+00 0.0 6.6e+04 5.4e+02 0.0e+00 28 0 0 0 0 29 0 0 0 0 0 DMPlexInterp 84 1.0 4.3219e-0158.6 0.00e+00 0.0 0.0e+00 0.0e+00 5.0e+00 0 0 0 0 0 0 0 0 0 1 0 DMPlexDistribute 1 1.0 3.0000e+03 1.5 0.00e+00 0.0 9.3e+05 2.3e+02 3.0e+01 88 0 0 0 2 90 0 0 0 3 0 DMPlexDistCones 1 1.0 1.0688e+03 2.6 0.00e+00 0.0 1.8e+05 3.1e+02 1.0e+00 31 0 0 0 0 31 0 0 0 0 0 DMPlexDistLabels 1 1.0 2.9172e+02 1.0 0.00e+00 0.0 3.1e+05 1.9e+02 2.1e+01 9 0 0 0 1 9 0 0 0 2 0 DMPlexDistField 1 1.0 1.8688e+02 1.2 0.00e+00 0.0 2.1e+05 9.3e+01 1.0e+00 5 0 0 0 0 5 0 0 0 0 0 DMPlexStratify 118 1.0 6.2852e+023280.9 0.00e+00 0.0 0.0e+00 0.0e+00 1.6e+01 1 0 0 0 1 1 0 0 0 2 0 DMPlexSymmetrize 118 1.0 6.7634e-02 2.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DMPlexPrealloc 1 1.0 2.3741e+01 1.0 0.00e+00 0.0 3.7e+06 3.7e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 DMPlexResidualFE 3 1.0 1.0634e+01 1.2 1.16e+09 1.0 0.0e+00 0.0e+00 0.0e+00 0 2 0 0 0 0 15 0 0 0 3569848 DMPlexJacobianFE 2 1.0 1.6809e+02 1.0 1.51e+09 1.0 6.5e+05 1.4e+06 0.0e+00 5 3 0 5 0 5 20 0 14 0 293801 SFSetGraph 87 1.0 2.7673e-03 3.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 62 1.0 7.3283e+0213.6 0.00e+00 0.0 2.0e+07 2.7e+04 0.0e+00 5 0 1 3 0 5 0 6 9 0 0 SFBcastOpBegin 107 1.0 1.5770e+00452.5 0.00e+00 0.0 2.1e+07 1.8e+04 0.0e+00 0 0 1 2 0 0 0 6 6 0 0 SFBcastOpEnd 107 1.0 2.9430e+03 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 80 0 0 0 0 82 0 0 0 0 0 SFReduceBegin 12 1.0 2.4825e-01172.8 0.00e+00 0.0 2.4e+06 2.0e+05 0.0e+00 0 0 0 2 0 0 0 1 8 0 0 SFReduceEnd 12 1.0 3.8286e+014865.8 3.74e+04 0.0 0.0e+00 0.0e+00 0.0e+00 1 0 0 0 0 1 0 0 0 0 31 SFFetchOpBegin 2 1.0 2.4497e-0390.2 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFFetchOpEnd 2 1.0 6.1349e-0210.9 0.00e+00 0.0 4.3e+05 3.5e+05 0.0e+00 0 0 0 1 0 0 0 0 2 0 0 SFCreateEmbed 3 1.0 3.6800e+013261.5 0.00e+00 0.0 4.7e+05 1.7e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFDistSection 9 1.0 4.4325e+02 1.5 0.00e+00 0.0 2.8e+06 1.1e+04 9.0e+00 11 0 0 0 0 11 0 1 1 1 0 SFSectionSF 11 1.0 2.3898e+02 4.7 0.00e+00 0.0 9.2e+05 1.7e+05 0.0e+00 5 0 0 1 0 5 0 0 2 0 0 SFRemoteOff 2 1.0 3.2868e-0143.1 0.00e+00 0.0 8.7e+05 8.2e+03 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFPack 1023 1.0 2.5215e-0176.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 1025 1.0 5.1600e-0216.8 5.62e+0521.3 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 54693 MatMult 1549525.4 3.4810e+00 1.3 4.35e+09 1.1 2.2e+08 6.1e+03 0.0e+00 0 8 8 7 0 0 54 62 21 0 38319208 MatMultAdd 132 1.0 6.9168e-01 3.0 7.97e+07 1.2 2.8e+07 4.6e+02 0.0e+00 0 0 1 0 0 0 1 8 0 0 3478717 MatMultTranspose 132 1.0 5.9967e-01 1.6 8.00e+07 1.2 3.0e+07 4.5e+02 0.0e+00 0 0 1 0 0 0 1 9 0 0 4015214 MatSolve 22 0.0 6.8431e-04 0.0 7.41e+05 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1082 MatLUFactorSym 1 1.0 5.9569e-0433.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.6236e-03773.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 897 MatConvert 6 1.0 1.4290e-01 1.2 0.00e+00 0.0 3.0e+06 3.7e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 MatScale 18 1.0 3.7962e-01 1.3 4.11e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 3253392 MatResidual 132 1.0 6.8256e-01 1.4 8.27e+08 1.2 4.4e+07 5.5e+03 0.0e+00 0 2 2 1 0 0 10 13 4 0 36282014 MatAssemblyBegin 244 1.0 3.1181e+01 6.6 0.00e+00 0.0 4.8e+06 2.5e+05 0.0e+00 0 0 0 6 0 0 0 1 19 0 0 MatAssemblyEnd 244 1.0 6.3232e+00 1.9 3.17e+06 6.9 0.0e+00 0.0e+00 1.4e+02 0 0 0 0 8 0 0 0 0 15 7655 MatGetRowIJ 1 0.0 2.5780e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCreateSubMat 10 1.0 1.5162e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 1.3e+02 0 0 0 0 7 0 0 0 1 13 0 MatGetOrdering 1 0.0 1.0899e-04 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatCoarsen 6 1.0 3.5837e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 MatZeroEntries 8 1.0 5.3730e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatAXPY 6 1.0 2.6245e-01 1.1 2.66e+05 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33035 MatTranspose 12 1.0 3.0731e-02 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 18 1.0 2.1398e+00 1.4 0.00e+00 0.0 6.1e+06 5.5e+03 4.8e+01 0 0 0 0 3 0 0 2 1 5 0 MatMatMultNum 6 1.0 1.1243e+00 1.0 3.76e+07 1.2 2.0e+06 5.5e+03 0.0e+00 0 0 0 0 0 0 0 1 0 0 1001203 MatPtAPSymbolic 6 1.0 1.7280e+01 1.0 0.00e+00 0.0 1.2e+07 3.2e+04 4.2e+01 1 0 0 2 2 1 0 3 6 4 0 MatPtAPNumeric 6 1.0 1.8047e+01 1.0 1.49e+09 5.1 2.8e+06 1.1e+05 2.4e+01 1 1 0 2 1 1 5 1 5 2 663675 MatTrnMatMultSym 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 MatGetLocalMat 19 1.0 1.3904e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 18 1.0 1.9926e-01 5.0 0.00e+00 0.0 1.4e+07 2.3e+04 0.0e+00 0 0 0 2 0 0 0 4 5 0 0 MatGetSymTrans 2 1.0 1.8996e-01 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 176 1.0 7.0632e-01 4.5 3.48e+07 1.0 0.0e+00 0.0e+00 1.8e+02 0 0 0 0 10 0 0 0 0 18 1608728 VecNorm 60 1.0 1.4074e+0012.2 1.58e+07 1.0 0.0e+00 0.0e+00 6.0e+01 0 0 0 0 3 0 0 0 0 6 366467 VecCopy 422 1.0 5.1259e-02 3.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 653 1.0 2.3974e-03 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 165 1.0 6.5622e-03 1.3 3.42e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 170485467 VecAYPX 861 1.0 7.8529e-02 1.2 6.21e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 25785252 VecAXPBYCZ 264 1.0 4.1343e-02 1.5 5.85e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 46135592 VecAssemblyBegin 21 1.0 2.3463e-01 1.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAssemblyEnd 21 1.0 1.4457e-04 1.6 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecPointwiseMult 600 1.0 5.7510e-02 1.2 2.66e+07 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 15075754 VecScatterBegin 902 1.0 5.1188e-01 1.2 0.00e+00 0.0 2.9e+08 5.3e+03 0.0e+00 0 0 10 8 0 0 0 82 25 0 0 VecScatterEnd 902 1.0 1.2143e+00 3.2 5.50e+0537.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1347 VecSetRandom 6 1.0 2.6354e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 DualSpaceSetUp 7 1.0 5.3467e-0112.0 4.26e+03 1.0 0.0e+00 0.0e+00 1.3e+01 0 0 0 0 1 0 0 0 0 1 261 FESetUp 7 1.0 1.7541e-01128.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 15 1.0 2.7470e-01 1.1 2.04e+08 1.2 1.0e+07 5.5e+03 1.3e+02 0 0 0 0 7 0 2 3 1 13 22477233 KSPSolve 1 1.0 4.3257e+00 1.0 4.33e+09 1.1 2.5e+08 4.8e+03 6.6e+01 0 8 9 6 4 0 54 72 20 7 30855976 PCGAMGGraph_AGG 6 1.0 5.0969e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 220852 PCGAMGCoarse_AGG 6 1.0 3.1121e+01 1.0 0.00e+00 0.0 2.5e+07 6.9e+04 5.5e+01 1 0 1 9 3 1 0 7 27 6 0 PCGAMGProl_AGG 6 1.0 5.8196e-01 1.0 0.00e+00 0.0 6.6e+06 9.3e+03 7.2e+01 0 0 0 0 4 0 0 2 1 7 0 PCGAMGPOpt_AGG 6 1.0 3.2414e+00 1.0 2.42e+08 1.2 2.1e+07 5.3e+03 1.6e+02 0 0 1 1 9 0 3 6 2 17 2256493 GAMG: createProl 6 1.0 4.0042e+01 1.0 2.80e+08 1.2 5.8e+07 3.3e+04 3.4e+02 1 1 2 10 19 1 3 16 31 34 210778 Graph 12 1.0 5.0926e+00 1.0 3.76e+07 1.2 5.1e+06 4.4e+03 4.8e+01 0 0 0 0 3 0 0 1 0 5 221038 MIS/Agg 6 1.0 3.5850e-01 1.3 0.00e+00 0.0 1.6e+07 1.2e+04 3.9e+01 0 0 1 1 2 0 0 5 3 4 0 SA: col data 6 1.0 3.0509e-01 1.0 0.00e+00 0.0 5.4e+06 9.2e+03 2.4e+01 0 0 0 0 1 0 0 2 1 2 0 SA: frmProl0 6 1.0 2.3467e-01 1.1 0.00e+00 0.0 1.3e+06 9.5e+03 2.4e+01 0 0 0 0 1 0 0 0 0 2 0 SA: smooth 6 1.0 2.7855e+00 1.0 4.14e+07 1.2 8.1e+06 5.5e+03 6.3e+01 0 0 0 0 3 0 1 2 1 6 446491 GAMG: partLevel 6 1.0 3.7266e+01 1.0 1.49e+09 5.1 1.5e+07 4.9e+04 3.2e+02 1 1 1 4 17 1 5 4 12 32 321395 repartition 5 1.0 2.0343e+00 1.1 0.00e+00 0.0 4.0e+05 1.4e+05 2.5e+02 0 0 0 0 14 0 0 0 1 25 0 Invert-Sort 5 1.0 1.5021e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 3.0e+01 0 0 0 0 2 0 0 0 0 3 0 Move A 5 1.0 1.1548e+00 1.0 0.00e+00 0.0 1.6e+05 3.4e+05 7.0e+01 0 0 0 0 4 0 0 0 1 7 0 Move P 5 1.0 4.2799e-01 1.1 0.00e+00 0.0 0.0e+00 0.0e+00 7.5e+01 0 0 0 0 4 0 0 0 0 8 0 PCGAMG Squ l00 1 1.0 3.0221e+01 1.0 0.00e+00 0.0 2.4e+06 5.8e+05 1.1e+01 1 0 0 7 1 1 0 1 22 1 0 PCGAMG Gal l00 1 1.0 8.7411e+00 1.0 2.93e+08 1.1 5.4e+06 4.5e+04 1.2e+01 0 1 0 1 1 0 4 2 4 1 1092355 PCGAMG Opt l00 1 1.0 1.9734e+00 1.0 3.36e+07 1.1 3.2e+06 1.2e+04 9.0e+00 0 0 0 0 0 0 0 1 1 1 555327 PCGAMG Gal l01 1 1.0 1.0153e+00 1.0 3.50e+07 1.4 5.9e+06 3.9e+04 1.2e+01 0 0 0 1 1 0 0 2 4 1 1079887 PCGAMG Opt l01 1 1.0 7.4812e-02 1.0 5.35e+05 1.2 3.2e+06 1.1e+03 9.0e+00 0 0 0 0 0 0 0 1 0 1 232542 PCGAMG Gal l02 1 1.0 1.8063e+00 1.0 7.43e+07 0.0 3.0e+06 5.9e+04 1.2e+01 0 0 0 1 1 0 0 1 3 1 593392 PCGAMG Opt l02 1 1.0 1.1580e-01 1.1 6.93e+05 0.0 1.6e+06 1.3e+03 9.0e+00 0 0 0 0 0 0 0 0 0 1 93213 PCGAMG Gal l03 1 1.0 6.1075e+00 1.0 2.72e+08 0.0 2.6e+05 9.2e+04 1.1e+01 0 0 0 0 1 0 0 0 0 1 36155 PCGAMG Opt l03 1 1.0 8.0836e-02 1.0 1.55e+06 0.0 1.4e+05 1.4e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 18229 PCGAMG Gal l04 1 1.0 1.6203e+01 1.0 9.44e+08 0.0 1.4e+04 3.0e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 2366 PCGAMG Opt l04 1 1.0 1.2663e-01 1.0 2.01e+06 0.0 6.9e+03 2.2e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 817 PCGAMG Gal l05 1 1.0 1.4800e+00 1.0 3.16e+08 0.0 9.0e+01 1.6e+05 1.1e+01 0 0 0 0 1 0 0 0 0 1 796 PCGAMG Opt l05 1 1.0 8.1763e-02 1.1 2.50e+06 0.0 4.8e+01 4.6e+03 8.0e+00 0 0 0 0 0 0 0 0 0 1 114 PCSetUp 2 1.0 7.7969e+01 1.0 1.97e+09 2.8 8.3e+07 3.3e+04 8.1e+02 2 2 3 14 44 2 11 23 43 82 341051 PCSetUpOnBlocks 22 1.0 2.4609e-0317.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 592 PCApply 22 1.0 3.6455e+00 1.1 3.57e+09 1.2 2.4e+08 4.3e+03 0.0e+00 0 7 8 5 0 0 43 67 16 0 29434967
--- Event Stage 1: PCSetUp
BuildTwoSided 4 1.0 1.5980e-01 2.7 0.00e+00 0.0 2.1e+05 8.0e+00 0.0e+00 0 0 0 0 0 0 0 1 0 0 0 BuildTwoSidedF 6 1.0 1.3169e+01 5.5 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 SFSetGraph 5 1.0 4.9640e-0519.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFSetUp 4 1.0 1.6038e-01 2.3 0.00e+00 0.0 6.4e+05 9.1e+02 0.0e+00 0 0 0 0 0 0 0 3 0 0 0 SFPack 30 1.0 3.3376e-04 4.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 30 1.0 1.2101e-05 1.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMult 30 1.0 1.5544e-01 1.5 1.87e+08 1.2 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 31 53 8 0 35930640 MatAssemblyBegin 43 1.0 1.3201e+01 4.7 0.00e+00 0.0 1.9e+06 1.9e+05 0.0e+00 0 0 0 2 0 28 0 10 51 0 0 MatAssemblyEnd 43 1.0 1.1159e+01 1.0 2.77e+07705.7 0.0e+00 0.0e+00 2.0e+01 0 0 0 0 1 26 0 0 0 13 1036 MatZeroEntries 6 1.0 4.7315e-0410.7 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatTranspose 12 1.0 2.5142e-02 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatMatMultSym 10 1.0 5.8783e-0117.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatPtAPSymbolic 5 1.0 1.4489e+01 1.0 0.00e+00 0.0 6.2e+06 3.6e+04 3.5e+01 0 0 0 1 2 34 0 32 31 22 0 MatPtAPNumeric 6 1.0 2.8457e+01 1.0 1.50e+09 5.1 2.7e+06 1.6e+05 2.0e+01 1 1 0 2 1 66 66 14 61 13 421190 MatGetLocalMat 6 1.0 9.8574e-03 1.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetBrAoCol 6 1.0 3.7669e-01 2.3 0.00e+00 0.0 5.1e+06 3.8e+04 0.0e+00 0 0 0 1 0 0 0 27 28 0 0 VecTDot 66 1.0 6.5271e-02 4.1 5.85e+06 1.0 0.0e+00 0.0e+00 6.6e+01 0 0 0 0 4 0 1 0 0 42 2922260 VecNorm 36 1.0 1.1226e-02 3.2 3.19e+06 1.0 0.0e+00 0.0e+00 3.6e+01 0 0 0 0 2 0 1 0 0 23 9268067 VecCopy 12 1.0 1.2805e-03 3.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 11 1.0 6.6620e-05 1.4 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 60 1.0 1.0763e-03 1.5 5.32e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 161104914 VecAYPX 24 1.0 2.0581e-03 1.3 2.13e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 33701038 VecPointwiseMult 36 1.0 3.5709e-03 1.3 1.60e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 14567861 VecScatterBegin 30 1.0 2.9079e-03 7.8 0.00e+00 0.0 1.0e+07 5.5e+03 0.0e+00 0 0 0 0 0 0 0 53 8 0 0 VecScatterEnd 30 1.0 3.7015e-0263.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSetUp 7 1.0 2.3165e-01 1.0 2.04e+08 1.2 1.0e+07 5.5e+03 1.0e+02 0 0 0 0 6 1 34 53 8 64 26654598 PCGAMG Gal l00 1 1.0 4.7415e+00 1.0 2.94e+08 1.1 1.8e+06 7.8e+04 0.0e+00 0 1 0 1 0 11 53 9 20 0 2015623 PCGAMG Gal l01 1 1.0 1.2103e+00 1.0 3.50e+07 1.4 4.8e+06 6.2e+04 1.2e+01 0 0 0 2 1 3 6 25 41 8 905938 PCGAMG Gal l02 1 1.0 3.4334e+00 1.0 7.41e+07 0.0 2.2e+06 8.7e+04 1.2e+01 0 0 0 1 1 8 6 11 27 8 312184 PCGAMG Gal l03 1 1.0 9.6062e+00 1.0 2.71e+08 0.0 1.9e+05 1.3e+05 1.1e+01 0 0 0 0 1 22 1 1 4 7 22987 PCGAMG Gal l04 1 1.0 2.2482e+01 1.0 9.43e+08 0.0 8.7e+03 4.8e+05 1.1e+01 1 0 0 0 1 52 0 0 1 7 1705 PCGAMG Gal l05 1 1.0 1.5961e+00 1.1 3.16e+08 0.0 6.8e+01 2.2e+05 1.1e+01 0 0 0 0 1 4 0 0 0 7 738 PCSetUp 1 1.0 4.3191e+01 1.0 1.70e+09 3.6 1.9e+07 3.7e+04 1.6e+02 1 1 1 4 9 100100100100100 420463
--- Event Stage 2: KSP Solve only
SFPack 8140 1.0 7.4247e-02 4.8 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 SFUnpack 8140 1.0 1.2905e-02 5.2 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1267207 MatMult 5500 1.0 2.9994e+01 1.2 3.98e+10 1.1 2.0e+09 6.1e+03 0.0e+00 1 76 68 62 0 70 92 78 98 0 40747181 MatMultAdd 1320 1.0 6.2192e+00 2.7 7.97e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 14 2 11 1 0 3868976 MatMultTranspose 1320 1.0 4.0304e+00 1.7 8.00e+08 1.2 2.8e+08 4.6e+02 0.0e+00 0 2 10 1 0 7 2 11 1 0 5974153 MatSolve 220 0.0 6.7366e-03 0.0 7.41e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 1100 MatLUFactorSym 1 1.0 5.8691e-0435.5 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatLUFactorNum 1 1.0 1.5955e-03756.2 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 913 MatResidual 1320 1.0 6.4920e+00 1.3 8.27e+09 1.2 4.4e+08 5.5e+03 0.0e+00 0 15 15 13 0 14 19 18 20 0 38146350 MatGetRowIJ 1 0.0 2.7820e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 MatGetOrdering 1 0.0 9.6940e-05 0.0 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecTDot 440 1.0 4.6162e+00 6.9 2.31e+08 1.0 0.0e+00 0.0e+00 4.4e+02 0 0 0 0 24 5 1 0 0 66 1635124 VecNorm 230 1.0 3.9605e-02 1.6 1.21e+08 1.0 0.0e+00 0.0e+00 2.3e+02 0 0 0 0 13 0 0 0 0 34 99622387 VecCopy 3980 1.0 5.4166e-01 4.3 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecSet 4640 1.0 1.4216e-02 1.2 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 VecAXPY 440 1.0 4.2829e-02 1.3 2.31e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 1 0 0 0 176236363 VecAYPX 8130 1.0 7.3998e-01 1.2 5.78e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 2 1 0 0 0 25489392 VecAXPBYCZ 2640 1.0 3.9974e-01 1.5 5.85e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 1 0 0 0 1 1 0 0 0 47716315 VecPointwiseMult 5280 1.0 5.9845e-01 1.5 2.34e+08 1.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 1 1 0 0 0 12748927 VecScatterBegin 8140 1.0 4.9231e-01 5.9 0.00e+00 0.0 2.5e+09 4.9e+03 0.0e+00 0 0 87 64 0 1 0100100 0 0 VecScatterEnd 8140 1.0 1.0172e+01 3.6 5.50e+0637.9 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 13 0 0 0 0 1608 KSPSetUp 1 1.0 9.5996e-07 3.1 0.00e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 0 KSPSolve 10 1.0 3.9685e+01 1.0 4.33e+10 1.1 2.5e+09 4.9e+03 6.7e+02 1 83 87 64 37 100100100100100 33637495 PCSetUp 1 1.0 2.4149e-0318.1 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 603 PCSetUpOnBlocks 220 1.0 2.6945e-03 8.9 1.46e+06 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0 0 0 0 0 0 540 PCApply 220 1.0 3.2921e+01 1.1 3.57e+10 1.2 2.3e+09 4.3e+03 0.0e+00 1 67 81 53 0 81 80 93 82 0 32595360
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants'
Mem.
Reports information only for process 0.
--- Event Stage 0: Main Stage
Container 112 112 69888 0. SNES 1 1 1532 0. DMSNES 1 1 720 0. Distributed Mesh 449 449 30060888 0. DM Label 790 790 549840 0. Quadrature 579 579 379824 0. Index Set 100215 100210 361926232 0. IS L to G Mapping 8 13 4356552 0. Section 771 771 598296 0. Star Forest Graph 897 897 1053640 0. Discrete System 521 521 533512 0. GraphPartitioner 118 118 91568 0. Matrix 432 462 2441805304 0. Matrix Coarsen 6 6 4032 0. Vector 354 354 65492968 0. Linear Space 7 7 5208 0. Dual Space 111 111 113664 0. FE Space 7 7 5992 0. Field over DM 6 6 4560 0. Krylov Solver 21 21 37560 0. DMKSP interface 1 1 704 0. Preconditioner 21 21 21632 0. Viewer 2 1 896 0. PetscRandom 12 12 8520 0.
--- Event Stage 1: PCSetUp
Index Set 10 15 85367336 0. IS L to G Mapping 5 0 0 0. Star Forest Graph 5 5 6600 0. Matrix 50 20 73134024 0. Vector 28 28 6235096 0.
--- Event Stage 2: KSP Solve only
Index Set 5 5 8296 0. Matrix 1 1 273856 0.
========================================================================================================================
Average time to get PetscTime(): 6.40051e-08 Average time for MPI_Barrier(): 8.506e-06 Average time for zero size MPI_Send(): 6.6027e-06 #PETSc Option Table entries: -benchmark_it 10 -dm_distribute -dm_plex_box_dim 3 -dm_plex_box_faces 32,32,32 -dm_plex_box_lower 0,0,0 -dm_plex_box_simplex 0 -dm_plex_box_upper 1,1,1 -dm_refine 5 -ksp_converged_reason -ksp_max_it 150 -ksp_norm_type unpreconditioned -ksp_rtol 1.e-12 -ksp_type cg -log_view -matptap_via scalable -mg_levels_esteig_ksp_max_it 5 -mg_levels_esteig_ksp_type cg -mg_levels_ksp_max_it 2 -mg_levels_ksp_type chebyshev -mg_levels_pc_type jacobi -pc_gamg_agg_nsmooths 1 -pc_gamg_coarse_eq_limit 2000 -pc_gamg_coarse_grid_layout_type spread -pc_gamg_esteig_ksp_max_it 5 -pc_gamg_esteig_ksp_type cg -pc_gamg_process_eq_limit 500 -pc_gamg_repartition false -pc_gamg_reuse_interpolation true -pc_gamg_square_graph 1 -pc_gamg_threshold 0.01 -pc_gamg_threshold_scale .5 -pc_gamg_type agg -pc_type gamg -petscpartitioner_simple_node_grid 8,8,8 -petscpartitioner_simple_process_grid 4,4,4 -petscpartitioner_type simple -potential_petscspace_degree 2 -snes_converged_reason -snes_max_it 1 -snes_monitor -snes_rtol 1.e-8 -snes_type ksponly #End of PETSc Option Table entries Compiled without FORTRAN kernels Compiled with 64 bit PetscInt Compiled with full precision matrices (default) sizeof(short) 2 sizeof(int) 4 sizeof(long) 8 sizeof(void*) 8 sizeof(PetscScalar) 8 sizeof(PetscInt) 8 Configure options: CC=mpifccpx CXX=mpiFCCpx CFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" CXXFLAGS="-L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack" COPTFLAGS=-Kfast CXXOPTFLAGS=-Kfast --with-fc=0 --package-prefix-hash=/home/ra010009/a04199/petsc-hash-pkgs --with-batch=1 --with-shared-libraries=yes --with-debugging=no --with-64-bit-indices=1 PETSC_ARCH=arch-fugaku-fujitsu ----------------------------------------- Libraries compiled on 2021-02-12 02:27:41 on fn01sv08 Machine characteristics: Linux-3.10.0-957.27.2.el7.x86_64-x86_64-with-redhat-7.6-Maipo Using PETSc directory: /home/ra010009/a04199/petsc Using PETSc arch: -----------------------------------------
Using C compiler: mpifccpx -L /opt/FJSVxtclanga/tcsds-1.2.29/lib64 -lfjlapack -fPIC -Kfast -----------------------------------------
Using include paths: -I/home/ra010009/a04199/petsc/include -I/home/ra010009/a04199/petsc/arch-fugaku-fujitsu/include -----------------------------------------
Using C linker: mpifccpx Using libraries: -Wl,-rpath,/home/ra010009/a04199/petsc/lib -L/home/ra010009/a04199/petsc/lib -lpetsc -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -L/opt/FJSVxos/devkit/aarch64/lib/gcc/aarch64-linux-gnu/8 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64 -Wl,-rpath,/opt/FJSVxtclanga/.common/MELI022/lib64 -L/opt/FJSVxtclanga/.common/MELI022/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -L/opt/FJSVxos/devkit/aarch64/aarch64-linux-gnu/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/usr/lib64 -Wl,-rpath,/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -L/opt/FJSVxos/devkit/aarch64/rfs/opt/FJSVxos/mmm/lib64 -Wl,-rpath,/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -L/opt/FJSVxtclanga/tcsds-1.2.29/lib64/nofjobj -lX11 -lfjprofmpi -lfjlapack -ldl -lmpi_cxx -lmpi -lfjstring_internal -lfj90i -lfj90fmt_sve -lfj90f -lfjsrcinfo -lfjcrt -lfjprofcore -lfjprofomp -lfjc++ -lfjc++abi -lfjdemgl -lmpg -lm -lrt -lpthread -lelf -lz -lgcc_s -ldl -----------------------------------------
participants (6)
-
Barry Smith
-
Jed Brown
-
Junchao Zhang
-
Mark Adams
-
Matthew Knepley
-
Stefano Zampini